一种聚类算法,根据样本的紧密程度进行样本的聚类,算法定义:核心对象、密度直达、密度可达、密度相连,对数据集进行聚类。
”密度 密度聚类算法 数据聚类 样本数据聚类 聚类“ 的搜索结果
一种通过快速搜索和查找密度峰值的聚类算法 来自科学的原始论文 《通过快速搜索和查找密度峰值进行聚类》 包括 这个集群存储库包括一个名为rawdata.dat的数据集和一个用于集群这些数据的算法。 原始样本分布,如下面...
二维人工数据集:6个 数据 xxx.txt 标签 xxx_cl.txt UCI真实数据集:10个 数据 xxx.txt 标签 xxx_label.txt
K均值(K-means)聚类是一种常用的无监督学习算法,用于将数据集中的样本分成K个不同的簇(cluster)。其基本思想是将数据集划分为K个簇,使得每个样本点都属于距离最近的簇的中心点,同时最小化簇内样本点之间的...
针对密度分布不均数据,密度峰值聚类算法易忽略类簇间样本的疏密差异,导致误选类簇中心;分配策略易将稀疏区域的样本误分到密集区域,导致聚类效果不佳的问题,本文提出一种面向密度分布不均数据的加权逆近邻密度...

模糊聚类算法FCM图像分割 完整的代码,方可运行;可提供运行操作视频!适合小白!
K-means聚类是一种广泛用于数据挖掘和机器学习的划分方法,它的目标是将n个观测点划分到k个簇中,使得每个点都属于离它最近的均值(即簇中心)对应的簇,从而使簇内的点尽可能地相似(即内聚度高),而不同簇的点尽...
引入样本点k近邻信息计算样本点的相对密度,借鉴快速搜索和发现密度峰值聚类(CFSFDP)算法的簇中心点识别方法,提出一种基于相对密度和决策图的聚类算法,实现对任意分布形态数据集聚类中心快速、准确地识别和有效聚类....
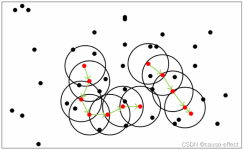
值得注意的是,这里给出的聚类的样本数据仅作为示例,读者完全可以根据自己的需求对其进行修改。...基本的K均值聚类算法matlab代码,给了一组样本数据作为例子,注释详细,聚类的样本数据可以进行修改。
聚类算法是一类将数据集分割成不同类或簇的算法,目的是使得同一个簇内的数据对象尽可能相似,而不同簇的数据对象尽可能不同。此外,聚类算法的评价指标也很重要,常用的评价指标包括轮廓系数、戴维森-伯尔丁指数等...



1)概述Hierarchical Clustering(层次聚类):就是按照某种方法进行层次分类,直到满足某种条件为止。主要分成两类:a)凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的...
常用数据聚类算法总结记录与代码实现[K-means/层次聚类/DBSACN/高斯混合模型(GMM)/密度峰值聚类/均值漂移聚类/谱聚类等]
针对谱聚类存在构造相似度矩阵时对尺度参数敏感以及处理多重尺度数据集效果不理想的缺陷, 提出一种基于密度调整的改进自适应谱聚类算法. 该算法将样本点所处领域的密度引入谱聚类, 利用密度差来调整样本点之间的...
代码主要做的是一种基于改进ISODATA算法的负荷场景曲线聚类,代码中,主要做了四种聚类算法,包括基础的K-means算法、ISODATA算法、L-ISODATA算法以及K-L-ISODATA算法,并且包含了对聚类场景以及聚类效果的评价,...
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、...利用已有数据,对31个省份进行聚类。

这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点,可发现任意形状的聚类, 且对噪声数据不敏感。但计算密度单元的计算复杂 度大,需要建立空间索引来降低计算量。 DBSCAN DBSCAN(Density-Based ...
K-means聚类算法是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象...
本人在此就不搬运书上关于密度聚类的理论知识了,仅仅实现密度聚类的模板代码和调用skelarn的密度聚类算法。 有人好奇,为什么有sklearn库了还要自己去实现呢? 其实,库的代码是比自己写的高效且容易,但自己实现...
运用数据集的自然分布信息自适应地计算出每一维较优的分割宽度,对不同的密度阈值统计其噪声样本对象的数量,绘制了噪声曲线,从噪声曲线中获得最佳的密度阈值,而且增加了类簇边缘处理技术,进一步提高了聚类的质量...
Python从零实现 K-mean 和K-中心点聚类算法的样本数据
为此,对原算法进行改进,在初步选取候选聚类中心的基础上,使用基于密度连通的算法优化选取聚类中心,然后使用大密度最近邻方法确定样本类别。实验证明,该方法能有效解决聚类个数和聚类中心无法确定的问题,同时在...
它是2014年在Science上提出的聚类算法,该算法能够自动地发现簇中心,实现任意形状数据的高效聚类。密度峰值聚类算法是对K-Means算法的一种改进,是一种不需要迭代的,可以一次性找到聚类中心的方法聚类方法。
密度峰值聚类算法(DPC)

推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地